�i�i�`�o�k�` 2006/01/28�j
�J�e�S���J���f�[�^�́u�U�z�x�v�ɂ�
�鋞������w�@��؋`��Y
�����ړx�̂���J�e�S���J���f�[�^�ɑ��āA�ׂ荇�����J�e�S���[�Ԃɂ͂P�A�Q����Ă���Q�Ƃ����悤�Ȑ��l��^���Ă��A�A���^�f�[�^�ɑ���u���ύ��v�ɑΉ�������̂ŎU�z�x�̎ړx��^���邱�Ƃ��ł���B�܂����ڎړx�̃f�[�^�ɑ��Ă��A�قȂ�J�e�S���[�ԑS�ĂɂP�̋�����������̂Ɖ��߂���A���l�̎U�z�x�̎ړx��^���邱�Ƃ��ł���B
���̘A���^�f�[�^![]() �ɑ��āA���ς�}�̂Ƃ��Ȃ���
�ɑ��āA���ς�}�̂Ƃ��Ȃ���
![]()
�ɂ���Ē�`�������̂� Gini�ɂ���ē������ꂽ�u���ύ��v�ŁA���̎ړx�͊e�f�[�^�Ԃ�(����ɂ��)�g����h�̕��ςł���B������A�W�����╽�ϕ��ȂǂƂǂ��悤�ɎU�z�x�̎ړx�Ƃ��ėp���邱�Ƃ��ł���B
�����ړx�̃J�e�S���J���f�[�^��i�Ԗڂ̃J�e�S���[�̊ϑ��x����![]() �Ƃ���B�ׂ荇�����J�e�S���[�Ԃ̋������P�ƍl�����
�Ƃ���B�ׂ荇�����J�e�S���[�Ԃ̋������P�ƍl�����
![]()
�Ƃ������Ή��ɂȂ�B
�����ŁA��P�A��Q�ݐϓx�������̂悤�ɒ�`����B
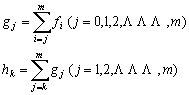
���̂Ƃ��A�U�z�x��\���ړx(��)��
![]()
�̂悤�ɗ^������B
����ɁA����̑���ɍ��̕������l����ƁA�A���^�f�[�^�̕W�����ɑΉ�����
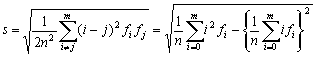
���A��͂�U�z�x�̎ړx�ƍl���邱�Ƃ��o����B
�w���{�l�̍����������x�̃f�[�^�ŁA�u���~�̍��A�����͕ʁX�ɏZ��ł���e���ƈꏏ�ɉ߂��������Ƃ������܂����v�Ƃ�������ɑ���p�^�[��
�@ �K���߂��������Ǝv���A
�A �ł���Ή߂��������Ǝv���A
�B ���܂�߂��������Ƃ͎v��Ȃ��A
�C �߂��������Ƃ͎v��Ȃ�
�ɂ��āA�j���ʂ̉̃f�[�^��
ordm=:194 516 73 41
ordf=:248 606 81 39
�̂悤�ɗ^����B����ɁA�N��K���ʂ̃f�[�^�����̂悤�ɓ��͂���B
|
Ord20=:20 104 13 7 ord25=:33 82 16 9 ord30=:21 97 19 6 ord35=:34 106 11 4 ord40=:49 163 17 12 ord45=:57 121 19 8 ord50=:42 106 20 6 ord55=:43 111 10 7 ord60=:59 107 10 9 ord65=:42 54 11 6 ord70=:42 71 8 6 |
ord_data 20 104 13 7 33 82 16 9 21 97 19 6 34 106 11 4 49 163 17 12 57 121 19 8 42 106 20 6 43 111 10 7 59 107 10 9 42 54 11 6 42 71 8 6 |
�����ŁA�����ړx�f�[�^�ɑ���U�z�x�g���h���Z�o����������̂悤�ɒ�`����B
div_u=:[:+/}.*[:}:+/\^:2
div_n=:[:(*<:)+/
div_v=:+:@div_u%div_n
|
div_u ord35 6818 div_n ord35 23870 div_v ord35 0.571261 div_v"1 ordm,:ordf 0.693836 0.673193 |
div_u ord65 5256 div_n ord65 12656 div_v ord65 0.830594 |
div_v"1 ord_data
0.574883 0.779548 0.623855 0.571261
0.632918 0.708656 0.690984 0.637771 0.715159 0.830594 0.734658
����ɁA��Θa�╽���a�����߂����
sum_ab=:[:+/^:2([:*/~])*[:|[:-/~i.@#
sum_sq=:[:+/^:2([:*/~])*[:*:[:-/~i.@#
�̂悤�ɒ�`����A
sum_ab ord35
13636
(sum_ab%div_n)ord35
0.571261
���U�z�x�g���h��^�����
sum_sq ord35
18460
div_s=:[:%:sum_sq%2:*[:*:+/
div_s ord35
0.619825
div_s ord65
0.808173
���U�z�x�g���h��^������ł���B
���ɁA���ڎړx�f�[�^�̏ꍇ�́A�X��J�e�S���[�ɔԍ���t���āAi�Ԗڂ̃J�e�S���[�̊ϑ��x����![]() �Ƃ���B�J�e�S���[�Ԃɂ͋����̂悤�Ȃ��̂��Ȃ�����
�Ƃ���B�J�e�S���[�Ԃɂ͋����̂悤�Ȃ��̂��Ȃ�����
![]()
�Ƃ������Ή��ɂȂ邩��A
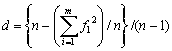
�����ύ��ɑΉ�����U�z�x�̎ړx��^���邱�ƂɂȂ�B
div_d=:13 :'(n-(+/*:y.)%n)%<:n=.+/y.'
�����w���{�l�̍����������x�̃f�[�^�ŁA�l�̕�炵���Łu�ł��d�����鍀�ځv��
|
�@ �ꐶ���������������ɂȂ邱�� �A �܂��߂ɕ��������グ�� �B �����̎�ɂ�������炵 �C �N���N�������̂ɕ�炷 |
�D������������炷 �E�Љ�̂��߂ɑS�Ă������� �F���̑� �G�c.�j�D |
�̒�����P�I��������A�j���ʂ̉̃f�[�^��
nomm=:323 55 695 363 126 90 28 44
nomf=:307 44 794 593 99 66 35 76
�̂悤�ɗ^����B����ɁA�N��K���ʂ̃f�[�^�����̂悤�ɓ��͂���B
|
nom20=:47 10 162 58 12 3 4 7 nom25=:55 11 131 58 12 7 1 5 nom30=:54 8 154 61 7 10 3 13 nom35=:52 10 133 89 16 11 7 11 nom40=:96 10 205 97 21 19 10 21 nom45=:74 10 178 95 23 18 9 15 nom50=:62 8 149 79 30 14 11 13 nom55=:65 11 128 86 29 25 7 13 nom60=:51 8 123 132 29 16 5 9 nom65=:37 5 65 89 28 15 3 5 nom70=:36 9 61 112 18 18 3 8 |
ord_data 47 10 162 58 12 3 4 7 55 11 131 58 12 7 1 5 54 8 154 61 7 10 3 13 52 10 133 89 16 11 7 11 96 10 205 97 21 19 10 21 74 10 178 95 23 18 9 15 62 8 149 79 30
14 11 13 65 11 128 86 29 25 7 13 51 8 123 132 29 16
5 9 37 5 65 89 28 15 3 5 36 9 61 112 18
18 3 8 |
|
div_d nom20 0.652132 div_d nom55 0.777147 div_d 6{.nom20 0.626018 div_d 6{.nom55 0.752119 |
div_d nomm 0.748483 div_d nomf 0.729313 div_d 6{.nomm 0.727045 div_d 6{.nomf 0.698709 |
div_d"1(6{."1 nom_data)
0.626018 0.684634 0.64858 0.704595
0.694871 0.704188 0.716143 0.752119 0.720235 0.748427 0.719336
|
div_d f=:23 2 21 1 8 15 1 3 0.77786 |
div_d 6{.f 0.752795 |